*GAN系列知识 GAN对抗网络初识 GAN-Basic-Theory 手动实现GAN网络生成动漫头像 GAN-4-f-GAN推导
学习了GAN的基本原理后,手动实现一个相当于GAN的 hello,world , 具体的工程见:
https://github.com/tzwx/DeepLearning
这里主要分析一下代码逻辑,贴上训练代码。
写代码的时候发现自己很生疏了,所以总结一下流程
先上图:训练了69个epoch的结果,设定的时2500epoch
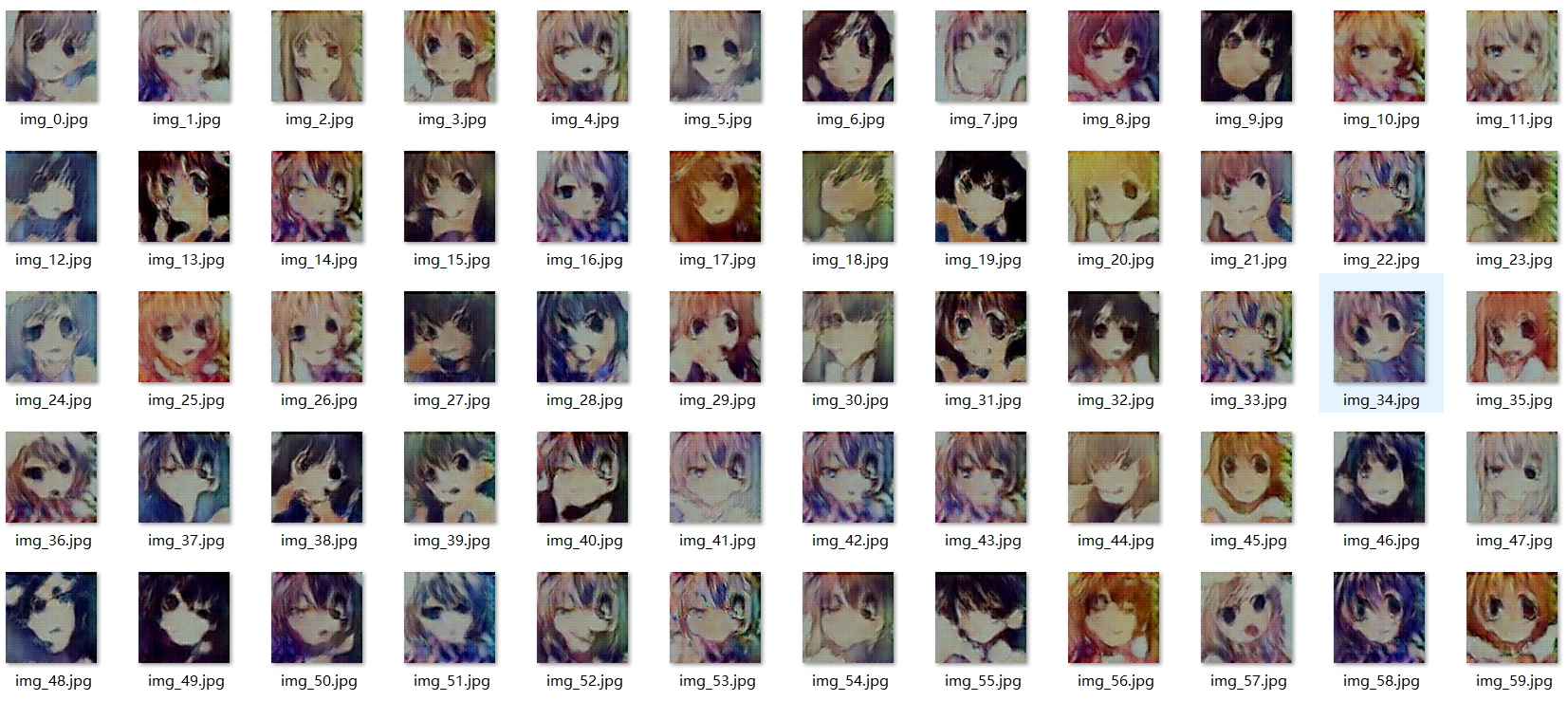
流程
定义网络结构
- 判别器就是几个卷积层(Conv)
- 生成器则是几个反卷积层(_deConv),最后接一个sigma函数分类
训练流程
trans = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((.5, .5, .5), (.5, .5, .5))
]
)数据处理
- 数据预处理,数据要先经过以上代码
- 定义label,用1表示realimg,0表示fakeimg,维度就是
BATCH_SIZE - 获取数据集,循环把100张图作为一个Batch,然后开始训练流程。
Training
- 定义损失函数
BCELoss,也就是二值的交叉熵 - 定义优化器Adam
- 定义学习率
- 优化器梯度清0
- 求得数据输出
- 用
loss function计算损失loss - loss 反向传播
- 更新参数
这个训练流程也是分类的流程。
思考
在训练过程中,判别器loss一直是比较小的(0.1,0.01,…),而生成器loss很大,(7-11不等),同时是一个互相博弈的过程,判别器loss减小时,生成器loss增加,反之亦然。
因为之训练了69个epoch,所以看不到最终的比较优化的结果,最后的结果应该是判别器的loss很大,生成器的loss很小才算训练结束。
代码
# @Time : 2020/2/29 17:31
# @Author : FRY--
# @FileName: train.py
# @Software: PyCharm
# @Blog :https://fryddup.github.io
from data_loader import get_img
from net.net import Generator
from net.net import Discriminator
import torch
import torch.nn as nn
import cv2
import numpy as np
import torchvision.transforms as transforms
BATCH_SIZE = 100
G_LEARNING_RATE = 0.0001
D_LEARNING_RATE = 0.0001
EPOCHS = 2500
trans = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((.5, .5, .5), (.5, .5, .5))
]
)
# Instance
g = Generator().cuda()
d = Discriminator().cuda()
# define loss
g_loss = nn.BCELoss() # Binary crossEntropy
d_loss = nn.BCELoss()
# define optimizer
g_optimizer = torch.optim.Adam(g.parameters(),lr=G_LEARNING_RATE)
d_optimizer = torch.optim.Adam(d.parameters(),lr=D_LEARNING_RATE)
# define labels
label_real = torch.ones(BATCH_SIZE).cuda()
label_fake = torch.zeros(BATCH_SIZE).cuda()
#all images
images_truth = get_img()
data_length = len(images_truth)
def train():
for epoch in range(EPOCHS):
# shuffle
np.random.shuffle(images_truth)
images_real_loader = []
count = 0
for index in range(data_length):
count = count + 1
images_real_loader.append(trans(images_truth[index]).numpy())
# images_real_loader[100,3,96,96]
if count == BATCH_SIZE:
count = 0 # reset
# Train Discriminator
# train real data to gpu
# if real -> d(real_img) = 1
images_real_loader_tensor = torch.Tensor(images_real_loader)
images_real_loader_tensor = images_real_loader_tensor.permute(0,3,1,2).cuda()
images_real_loader.clear()
# graddient _ zero
d_optimizer.zero_grad()
# real image output_66
realimage_d = d(images_real_loader_tensor).squeeze() # descent [100,1,1,1] -> [100,1]
# loss
d_realimg_loss = d_loss(realimage_d, label_real)
# loss backward
d_realimg_loss.backward()
# train generate data
# if generator d(generate_img) = 0
images_fake_loader = torch.randn(BATCH_SIZE, 100, 1, 1).cuda()
# detach() g no gradient -> fix generator
images_fake_loader_tensor = g(images_fake_loader).detach()
fakeimg_d = d(images_fake_loader_tensor).squeeze()
d_fakeimg_loss = d_loss(fakeimg_d, label_fake)
d_fakeimg_loss.backward()
d_optimizer.step()
# Train Generator
fake_data = torch.randn(BATCH_SIZE, 100, 1, 1).cuda()
g_optimizer.zero_grad()
generator_images = g(fake_data)
generator_images_score = d(generator_images).squeeze()
gen_loss = g_loss(generator_images_score, label_real)
gen_loss.backward()
g_optimizer.step()
print("Current epoch:%d, Iteration: %d, Discriminator Loss: %f, Generator Loss: %f"
% (epoch, (index//BATCH_SIZE)+1,
(d_realimg_loss+d_fakeimg_loss).detach().cpu().numpy(),
gen_loss.detach().cpu().numpy()))
torch.save(g, "pkl"+str(epoch)+"generator.pkl")
if __name__ == "__main__":
train()