*GAN系列知识 GAN对抗网络初识 GAN-Basic-Theory 手动实现GAN网络生成动漫头像 GAN-4-f-GAN推导
GAN基本原理
参考链接:https://www.bilibili.com/video/av24011528?from=search&seid=17842693444993179137
首先,GAN全称是Generative Adversarial Nets ,一般叫对抗网络。由两部分组成:Generator(生成器)、Discrimator(判别器)。
- Generator
生成器可以认为就是一个Neural Network。以CV为例,现在的目标是生成图片,则生成器的工作就是输入一个vector,然后输出一张图像(动漫头像),其中某一维可能对应头发长短,另一维对应眼睛颜色,这样通过调整向量就可以控制自己需要的头像,类似于下图:

- Discrimator
判别器也是一个Neural Network, 顾名思义,是判断生成器生成的东西的好坏,输入是一张image(动漫头像), 输出一个scalar(标量,数字) , 衡量生成器生成的image的好坏程度。如下图:
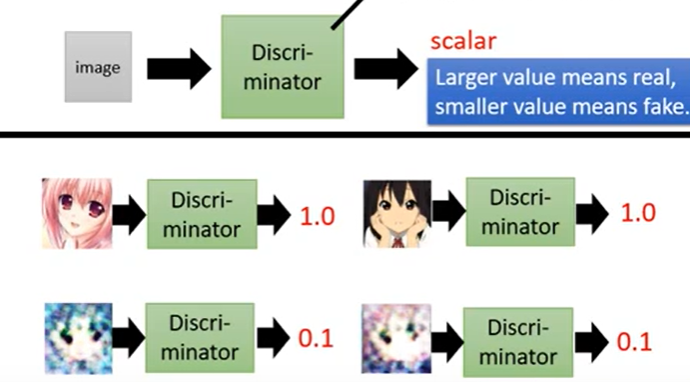
GAN算法流程 Algorithm
- 初始化 Generator 、Discrimator
- 在每一个迭代中:
- 固定生成器,训练判别器,生成器目标是欺骗过判别器,也就是生成器生成的图片判别器给出的分数越高越好
- 固定判别器,训练生成器
- 重复以上步骤,判别器和生成器在同时进行学习,同时进化,相互博弈,直到生成器能瞒过判别器就算是训练好了
Structured Learning
结构化学习是很有挑战性的,例如生成图像,很重要的一个东西是像素之间的关系,像素本身是没有什么错误的,但是它们之间的关系很重要。
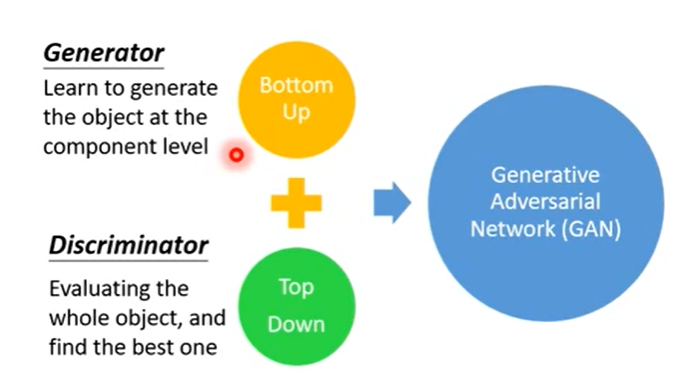
- Generator 是先画每一个部件,最后形成一幅 image;
- Discrimator 则是整体上判断图像好不好,并且可以挑选出来最好的图像;
两者结合起来就是GAN对抗网络了,可以发挥各自的性能,如下图:
Q1:为什么Generator(生成器)不自己学习呢?
首先生成器是输入一个vector,输出是image,这和Auto Encoder (自编码器)技术中的Decoder(解码器)工作室一样的,也就是说Decoder就是一个Generator。
Auto Encoder自编码器是有缺陷的,也就是说一张图片只是对应到一个点,从这个点解码出图像,如果取一个没有出现过的点进行解码,解码出来的就是noise了,也就是说只能解码出现过的,因此出现了VAE技术:
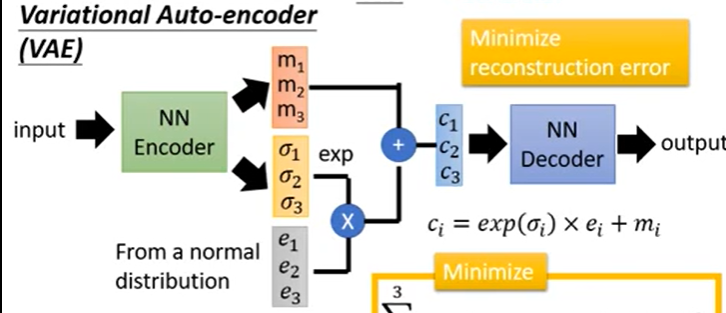
也就是在编码图像时添加了噪音等,这样采样任何一个点都会解码出来比较真实的图像。在这两种技术中都有Decoder, 那么这种技术缺少了什么?
对于生成器来说,部件之间的关系很重要,而在解码器中神经元相互之间是没有关系的,也就是部件之间很难产生联系,这就直接导致很容易失去大局观,整体性就比较差。
关于部件之间的练习,可以看这个例子:

人眼来判断的话当然觉得下面看两幅图比较好,但是Decoder则会认为上面两幅图比较好,因为逐像素比较确实是前两幅图误差小,这就很容易看出来没有考虑到整体性。事实上Decoder很难做到这一点。
Q2:为什么Discrimator(判别器)不自己生成呢?
判别器既然可以判断生成的图像好不好,为什么不自己生成呢?

还是用上面的例子,比如判别器可能有这样一个卷积核,即中心有颜色其他地方没有,看到这样的就给图像低分,判别器很容易判断图像整体性。
事实上判别器就像是批评家,比较形象的可以说是**“键盘侠”**,不管你说什么他只给说哪里不好,你要问他什么是好的他可能说不出来这样子。严密的论证可以看文章开始的视频链接讲到的,简单来说就是:
- 训练判别器首先不能只是正样本,也需要一些负样本,而我们手上是没有负样本的,因此需要生成负样本
- 要产生比较好的负样本就需要一个比较好的判别器才能找到比较好的负样本
因此,就陷入了鸡生蛋、蛋生鸡的问题。因此训练单独的一个判别器首先要假定已经有比较好的负样本。训练流程类似,可以看视频讲解。
Summary
总结一下,生成器和判别器各自的优势劣势:

Additional
- 上面提到GAN训练时要先训练判别器,这是为什么?后面文章会有公式理论说明这个问题。
- 上面提到的
Auto EncoderVAE这两种编码技术随后文章会详细讨论细节问题。