*GAN系列知识 GAN对抗网络初识 GAN-Basic-Theory 手动实现GAN网络生成动漫头像 GAN-4-f-GAN推导
这篇文章主要来讨论下GAN基础的理论、公式推导。
KL 散度
KL Divergence 指的是相对熵,其用来衡量两个取值为正的函数或概率分布之间的差异;
相对熵 = 某个策略的交叉熵 - 信息熵(根据系统真实分布计算而得的信息熵,为最优策略) , 公式如下:
复习一下,交叉熵是使用非真实分布,信息熵是使用真实分布计算得到的。
JS 散度
JS Divergence 是 KL散度的变体,衡量两个分布之间的相似性。公式如下:
Formula Of GAN
首先,生成器要做的事情就是生成一个最靠近真实data的分布,这在之前可以用最大似然估计来找这样的一个分布,最大似然估计实际上可以与KL散度扯上关系:

这里面需要注意的是约等于 这一步,意思是最大值求和m笔data的概率其实就是求x服从于真实分布的情况下概率的最大值,所以就 = 下面的积分,而下面的积分后边减去的一项不影响求最大值,所以再意思上是相等的,但是真实值上并不相等。然后上面的公式主要是来说明:
最大化最大似然估计概率就是最小化KL散度,即:
所以要训练Generator,也就是要计算出真实数据和生成数据之间的散度,而Discriminator则可以做到这一件事。
在训练Discriminator时,在固定住Generator的情况下进行,定义对象方程:
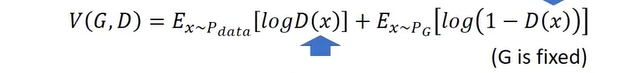
这里后面一项之所以要定义为1-D(x),是因为判别器做的事情是给Pdata高分,给Pg低分,也就是使得生成的数据和真实的数据分布的散度最大。因此在x服从Pg分布时,写1-D(x) 就可以最大化这个式子,比较容易train,即:
实际上,当生成的图像和真实图像散度比较大,相似度比较小时,判别器是很好训练的,而相似度比较大就比较难训练,所以训练好的判别器其实就是在最大化生成的图像和真实图像的散度。下面证明这一项就是在最大化JS 散度:



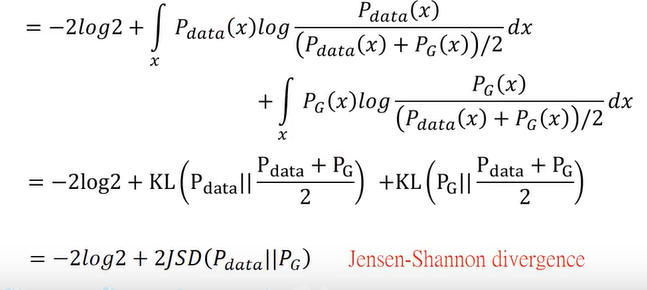
这里最后一步可以参考一开始文章提到的JS散度对比一下公式就会明白。所以此时:
此时梯度下降法求解G*:
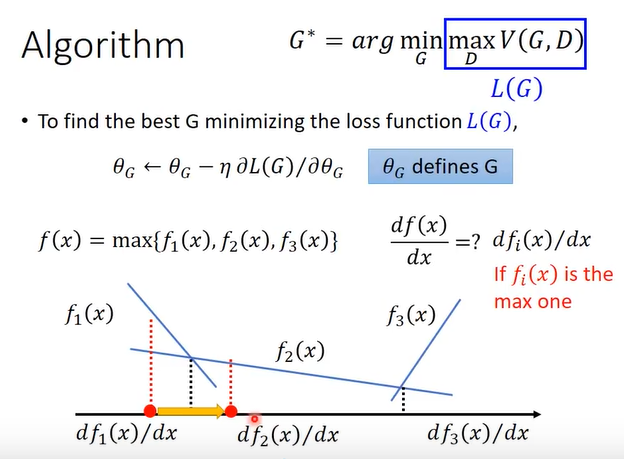
这里的max取微分可以看作分段函数求微分。所以现在已经可以铜鼓哦梯度下降法来更新生成器了,然后进行算法:

这里有一个问题,事实上更新G1参数真的是在减小JS散度吗?

举个例子如上图,在G更新后,G的分布已经变了(由左到右),此时的D0*依然是固定的未发生变化,因此此时的D0*已经不再是max值了,因此此时(伪)max V(G,D) 便不再是JS散度了。所以有个假设,G的变化不能太大,每次更新一点点,否则误差会过大。
以是就是GAN的基础理论公式推导。
Practice
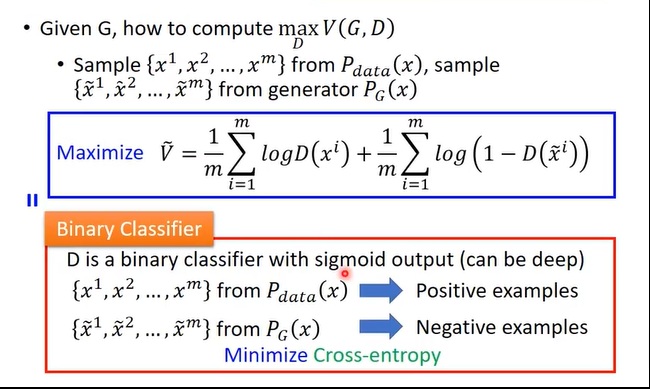
最后整体回顾一遍算法流程:

**注意的是一般Generator只训练一次 **。原因前面说了 。
以上就是GAN 对抗网络的 Basic Theory,还有其他的一些之后的细节可以看李宏毅老师的视频。有错误欢迎指正!