入门系列文章: 深度学习入门系列一-梯度下降法 深度学习入门系列一-梯度下降法-② 梯度下降法3 深度学习入门系列4-反向传播BP算法 深度学习入门系列-逻辑回归 深度学习入门系列6-Convolution-Neural-Network-CNN-卷积神经网络 深度学习入门系列7-Tips-For-DeepLearning-全程高能 深度学习入门系列8-Tips-For-DeepLearning-2-全程高能
我是研究CV方向的,但是深度学习我只是在学习Tensorflow书的时候学过里面的东西,很多东西讲的过于简单,理解并不直观,所以最近就在学习深度学习的视频,是李宏毅老师讲的,内容很生动,解决了我很多疑惑,附上视频地址→,看视频就要跟着老师推导一遍公式,也是理解了很多内在的东西。
bilibili : https://www.bilibili.com/video/av48285039?p=43
Youtube: https://www.youtube.com/watch?v=D_S6y0Jm6dQ
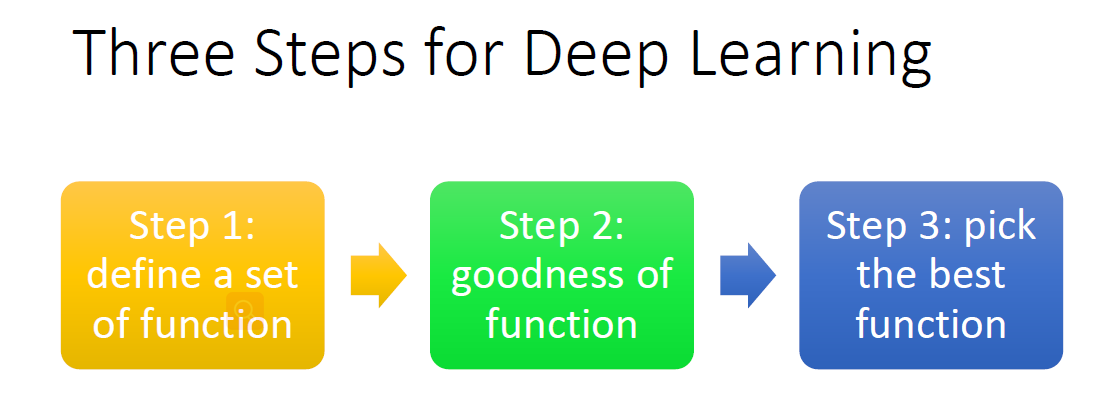
概述:深度学习流程
深度学习过程于机器学习类似,这里就先讲一下机器学习的,深度学习后面会讲到。对于一个特定的机器学习 Machine Learning任务,简单来说有以下固定的三个步骤:
-
定义一系列的函数 ;
-
评价函数的好坏,也就是定义损失函数;
-
找出最好的函数(model)
在定义好函数和确定损失函数之后,就要开始调整参数。这时候就需要用到梯度下降法了。
梯度下降法概述
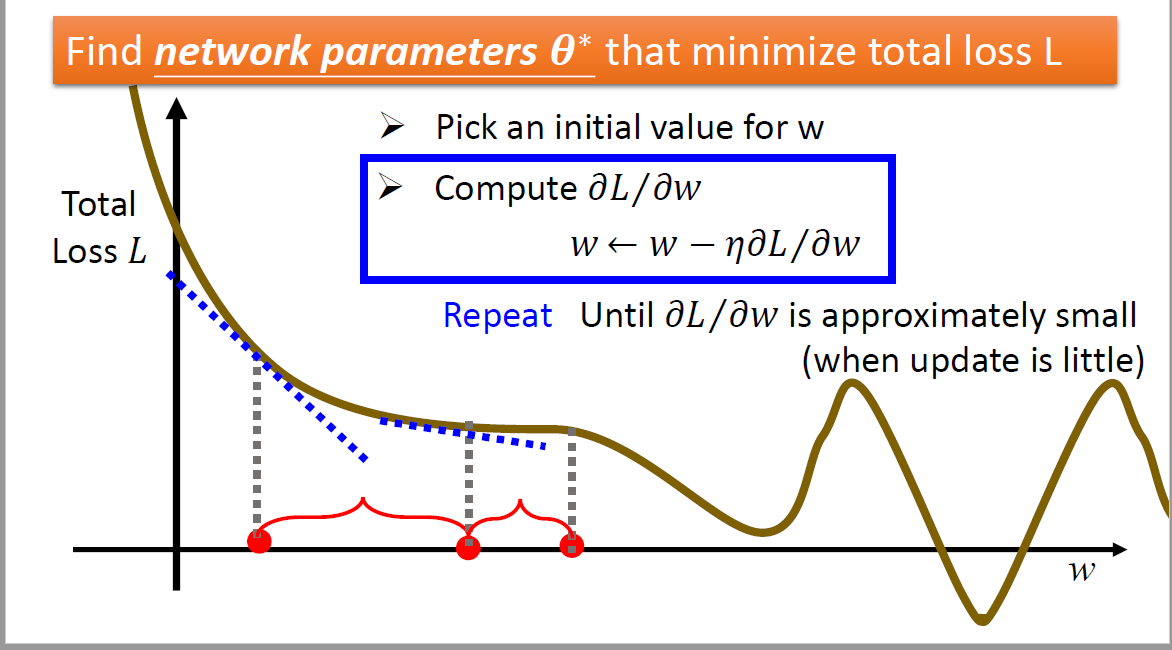
调整参数就是为了师让损失函数最小,也就是选择出最好的函数 (Model)。先讲一下梯度下降法更新参数的真个流程。
梯度
首先,梯度Gradient,就是在这一点的微分(偏导数),也就是曲线在该点切线的斜率,高等数学就有讲过;不理解微分就可以当作是等高线图的法线方向。梯度代表了函数上升最快的方向,所以一个函数在一点求出梯度,然后按照梯度的反方向偏移就是减小最快的。
所以这里也可以得知,首先需要一个可微的函数。
流程
-
假设对于参数w,要更新w,首先要初始化w的值,可以随机初始化一个值,当然也有其他方法这里并不关心
-
计算损失函数 Loss function,L(·)对于参数w在该点处的偏导数,这就是函数在这一点的梯度。为什么是偏导数,因为参数不只是w一个,也有bias偏置b。
-
计算出梯度就知道在那个方向上损失函数降幅最大,就开始更新参数,直到一个局部最小值。
w_new = w_original - lr*w_original_graident -
重复 2、3 步骤,就可以不断调整参数
Note :
- 上述伪代码中有一个 lr参数,这是学习率Learning Rate,学习率决定了每次下降的步长,学习率影响还是比较大的,过小需要的时间太久,过大的话又会震荡不能收敛,这也是梯度下降法的一个存在的问题,后续会继续讲。
- 上述第三步提到会函数会降低到局部最小值,这里整个是以线性函数为例,故不用考虑是否会降到局部最小值。