RNN,循环神经网络,一般用来处理序列化任务。例如一个句子就是一个词序列;一段视频就是一个图像序列;人讲一句话也是一个序列,处理序列就考虑到了时间维的信息。
SIMPLE RNN
最简单的一个RNN循环神经网络就是存储了上一时刻的隐藏状态的值。简单的讨论一下RNN的设计结构。
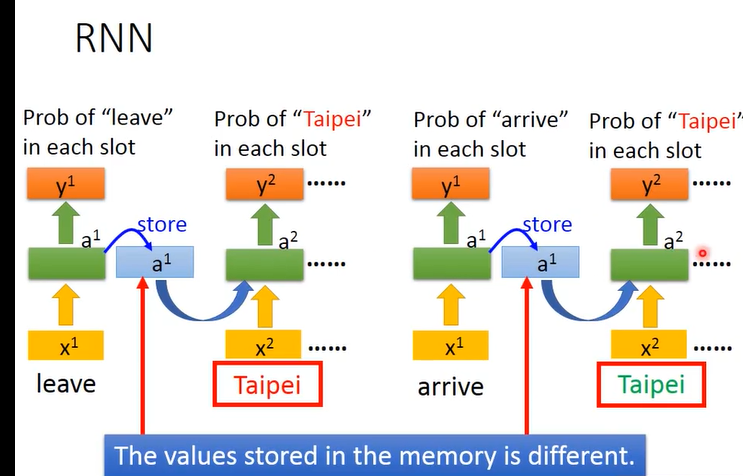
假设只有一个隐藏层,有两个句子:
- leave Taipei
- arrive Taipei
如果采用一般的神经网络,见到Taipei这同一个词汇,输出的值都是相同的,与预期任务就不符合了。
首先leave作为第一时刻的输入,产生一个值;隐藏状态值是a1要存储起来,如上图的蓝色a1,然后下一时刻输入Taipei就同时收到x2、a1 的影响。后面的也同理,因此同一个输入就有不同的输出。
上面是一个简单的单向的RNN,还有双向的RNN,如下图:
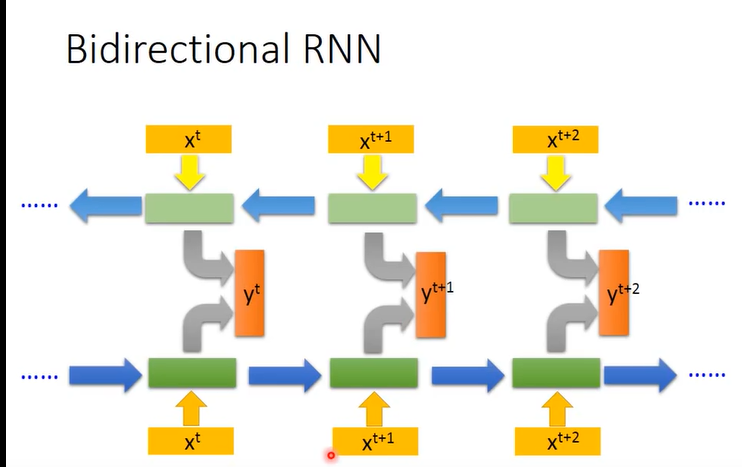
训练一个正向的和一个反向的循环神经网络,然后把同一时刻(xt)两个网络的隐藏层拿出来同时计算该时刻的输出(yt).也就是说计算每一时刻的输出都要考虑到整个序列。
Long Short-term Memory(LSTM)
上面的RNN是一个简单的循环神经网络的结构,它的记忆非常非常有限,只能记住前一个时刻的,这对我们来说仍然是不足的,因此需要记住更久的东西,就有了LSTM。(注意名字,是多个短期记忆,一般叫长短期记忆网络,应该是很长的短期记忆网络,而不是长-短 期记忆网络。)
LSTM网络结构如下:
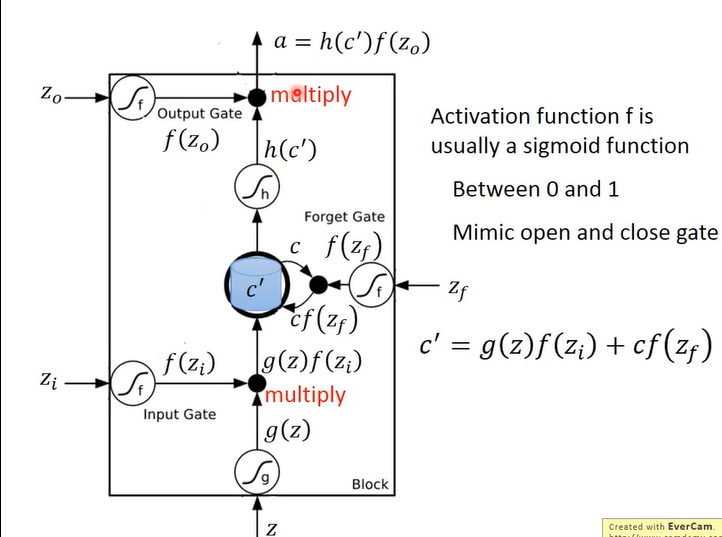
它的核心在于中间蓝色部分的记忆细胞。
它的计算过程观察上图,首先有 四个gate,这四个门可以理解为四个控制信号,其中
- 表示的是要输入的信息的信号;
- 表示的是输入门的信号;
- 表示的是遗忘门的信号;
- 表示的是输出门的信号;
其中, 的值就是输入 乘上四个矩阵得到的,整个流程如下图:
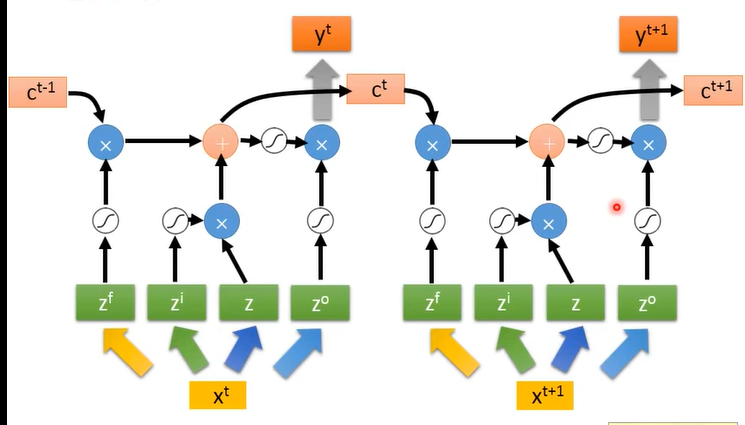
细胞贯穿主线,xt的输入得到输出yt嘛,中间经过一系列的组合计算;注意上图中z其实也是有激活函数的,z激活函数是tanh().
上图只是展示了LSTM计算过程,实际操作时会照以下操作(单个LSTM):
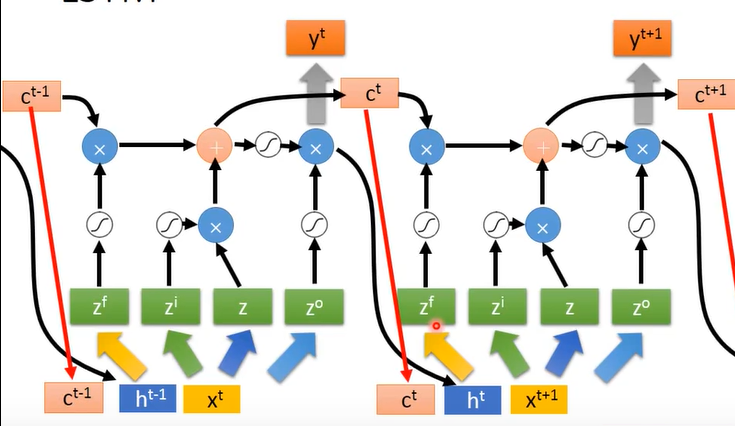
会把前一时刻的输出值()、记忆单元值()、这一时刻的输入值 ()堆在一起,一起再去计算,堆在一起就是torch中的级联:torch.cat()
在实际训练网络时单个LSTM肯定是不够的,所以需要计算多个的,此时:
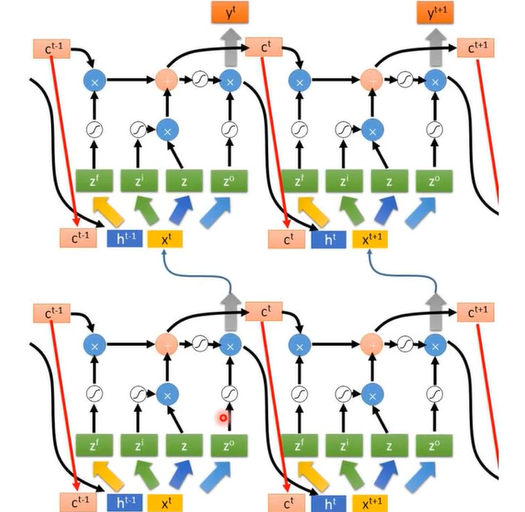
横向的都是同一个LSTM,纵向的是堆起来的不同的LSTM模块。
下面总结一下LSTM模块:
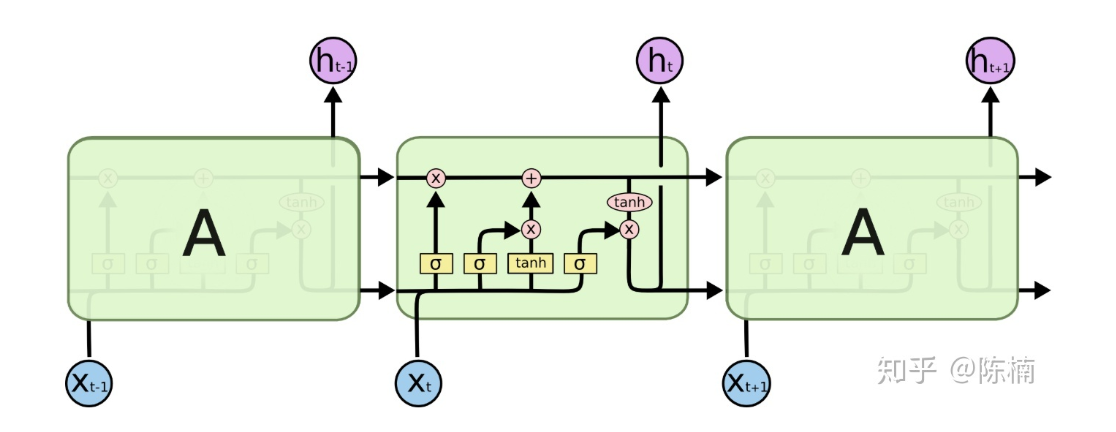
这张图实际上前一时刻的细胞状态是没有和输入叠在一起的。以上就是整个LSTM架构,而它的几个变体都是大同小异。
Why Lstm not Simple-RNN?
RNN基础模型一般不是很容易训练起来,面临梯度弥散、梯度爆炸的问题。
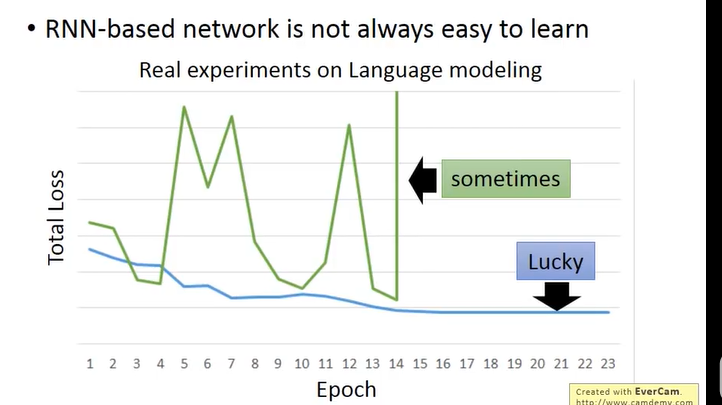
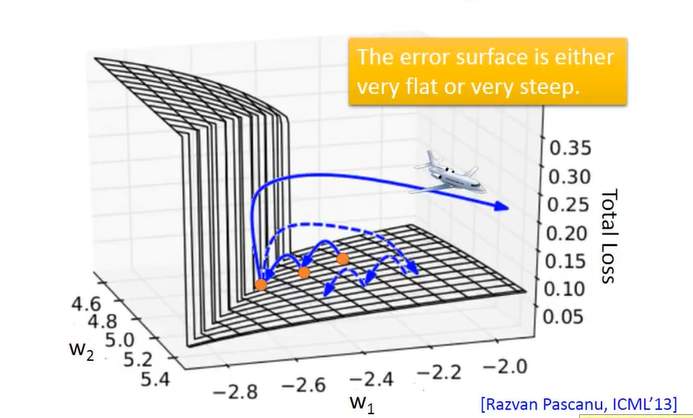
如图,绿色的线条是实验的RNN的loss,它震荡不收敛。造成这个的原因在于Error Surface is rough:
 **
**
如图,如果梯度下降法刚好更新到断层上,此时梯度骤升,学习率比较大就会飞出去很远,就直接没有了
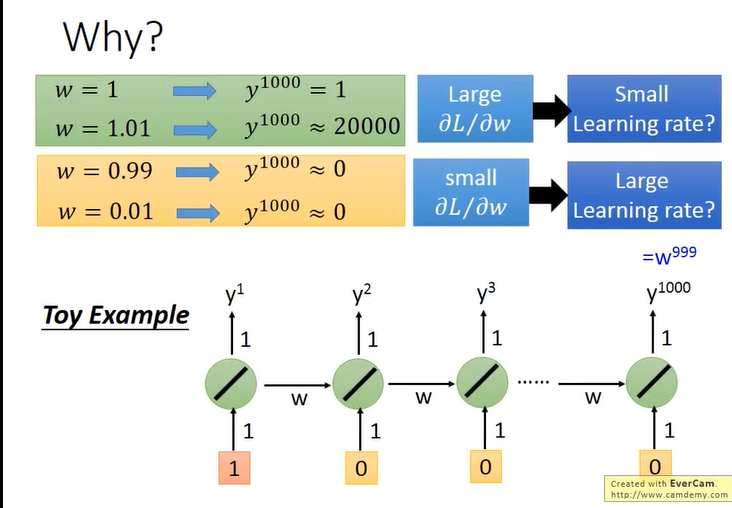
这就很直观的解释了原因,每次RNN都会用前一次的输出不加控制的影响下一个结果,也就是护送每次都hi把Memory的值完全变化掉。w是指数级就很容易有Gradient Vanish(explore) 的问题。
而LSTM,
-
它把Memory的值*一个值+input*一个值更新到Cell中,也就是说它的Memory和input是相加的;
-
如果weight影响到记忆细胞的值,则一直会存在,除非遗忘门决定遗忘。而RNN则会一直洗掉。因此LSTM解决了梯度弥散问题。
-
一般遗忘门经常要开着,bias要比较大。