最近学习了很火的 Mamba 模型,此处做一个简单 High-level 的记录,后续有新理解在补充细节 Mamba 全称为 Selective State Space Models (SSMs),是一种新的模型架构,主要目的是解决长序列建模(long range dependency)。 直观的说,该模型是为了改进 Transformer 计算效率以及 window attention,与序列长度成线性关系(Transformer为 )。
相关学习资料
- 原文/Code:《Mamba: Linear-Time Sequence Modeling with Selective State Spaces》)
- 相关前身论文:《Efficiently Modeling Long Sequences with Structured State Spaces》
- 知乎讲解:如何理解 Mamba 模型 Selective State Spaces?
- Blog: The Annotated S4
- Github related papers: Awesome-Mamba-Collection
系列论文更新
- Vision Mamba - Efficient Visual Representation Learning with Bidirectional State Space Model
- VMamba - Visual State Space Model
- U-Mamba - Enhancing Long-range Dependency for Biomedical Image Segmentation
- Mamba-UNet - UNet-Like Pure Visual Mamba for Medical Image Segmentation
- U-shaped Vision Mamba for Single Image Dehazing
系列背景
很长的序列建模用现有的 RNN/CNN/Transformer 很困难,状态空间模型 State Space Model (SSM) 则比较合适。
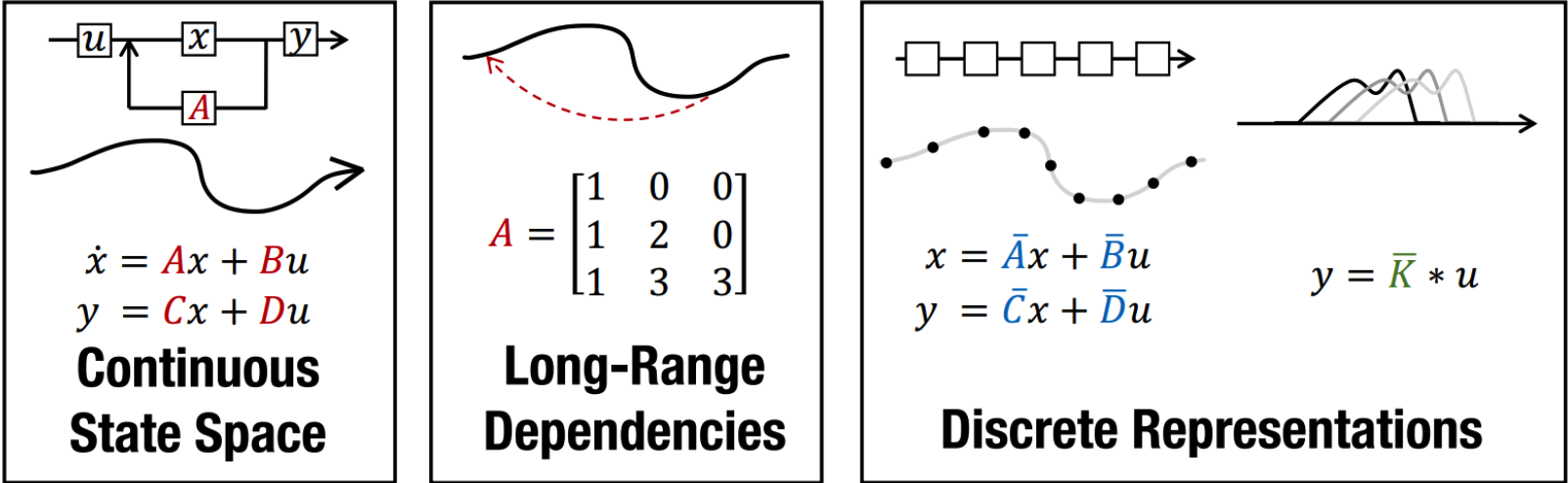
Vanilla SSM (A Continuous-time Latent State Model)
- Step1—Definition
原始的状态空间模型可以由 四个参数形式化。 可以忽略,设为 0 就是一个残差连接,不影响计算。简单理解上述公式,SSM目的是将一个 的信号首先映射为一个状态表示向量 同时计算输出。公式 [微分] 定义了状态向量的变化。 Tensor Dimension:
- Step2—Discrete-time:Recurrent Representation 为了将连续的 SSM 应用于离散数据,需要通过 (Step size) 对其进行离散化 (blinear method 双线性方法对状态矩阵 求了近似 ),此时上述公式形式化为:
离散化之后可以学习 seuqence-to-sequence 的 mapping :
这里的公式其实就和 RNN很类似了,考虑当前状态和历史状态。
- Step3—HiPPO Matrix (Addressing Long-Range Dependencies) 在实际应用中,直接学习这几个参数矩阵结果很差,由于梯度爆炸/消失等问题。此时引入HiPPO 理论来学习一个 矩阵,可以解决实际学习问题。这里只记录一下基本过程/公式/理论,具体的内容可以先不用理解。

Structured State Space Model (S4 Model)
S4模型是 Mamba 的前置工作,主要是因为上述 SSM学习矩阵参数时计算量太大,因此采用了对角化,Normal Plus Low-Rank 来将上述学习的 矩阵进行分解:
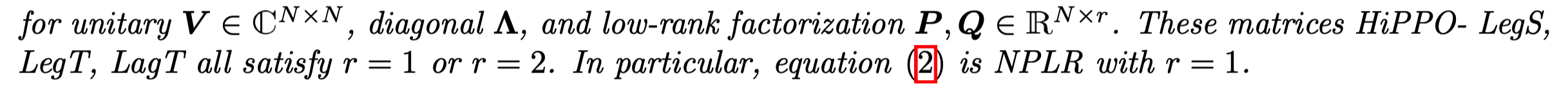
Selective State Space Model (Mamba)
Mamba主要解决两个问题:
- 之前的 S4 模型学习的时候参数是固定的,不能基于输入做出改变,也就是灵活性不高,影响建模能力 Time-invariant
- 把 S4 参数矩阵改进成基于输入的函数,无法进行类卷积的并行运算了会很慢,需要提高计算效率,提出硬件感知的并行扫描算法 (关于 efficient 计算不是我关注的,所以我没有重点去看这部分)
Mamba 公式起源在上述其实已经提过了,这里在重新写一下:
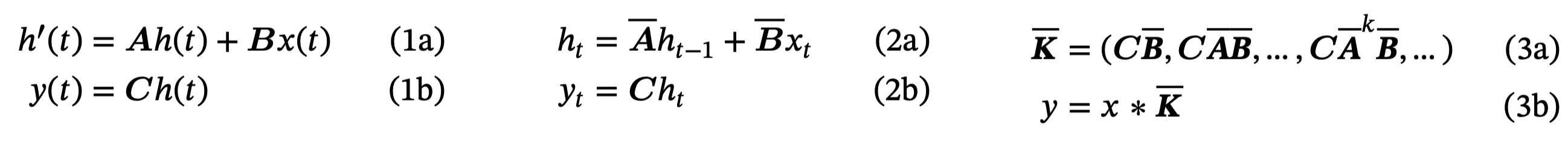
- 首先,(2a) (2b) 可以看出 Mamba 与 RNN 非常类似
- 其次,公式 3 是通过将 2 进行展开得出的,相当于是一个序列卷积(Global Attention)。关于这点可以参考知乎上,我也手动推过确实没问题
随后,这里用 ZOH (zero-order hold) 理论进行离散化:
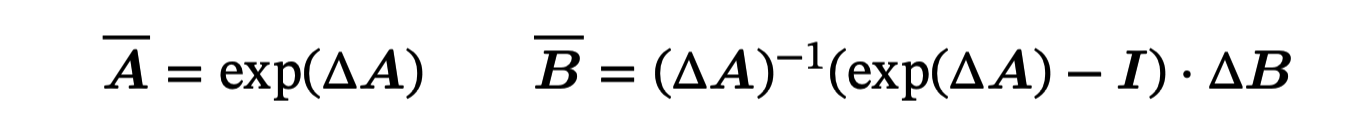
解决方案

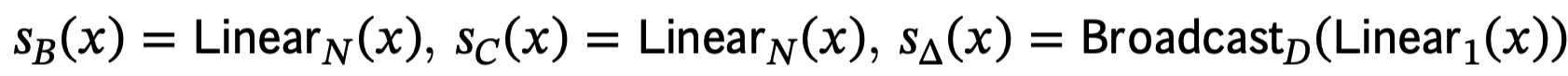
- 在提高建模能力方面,主要是把参数学习的维度和方式改了。
相比于 S4,
- 矩阵未发生变化(S4推导的分解后的矩阵); 表示对于每一维都有一个学习的 维的状态矩阵,但是不同输入都是 share 的;但是由于, 这个学习矩阵会被 调制成 Time-Varying
- 矩阵以前是每个通道有一个 维的,现在是对于每一个 sample(batch * length)都有一个 维的,但是注意这里每个通道是一样的,这里感觉就是降低计算量。
- 以前是对于每一维有一个,现在是对于每个sample 的每个维度都有一个 time step 参数; 越大,越聚焦于当前时刻输入;反之越小越关注历史记忆信息。
- **在计算方面,由于现在的时变性,就无法抽象出公式(3a)的归纳了,由于 等等。这里作者提出了”Parallel Scan”来进行并行,提高效率,这里我就没关注了。
Mamba 和 RNN
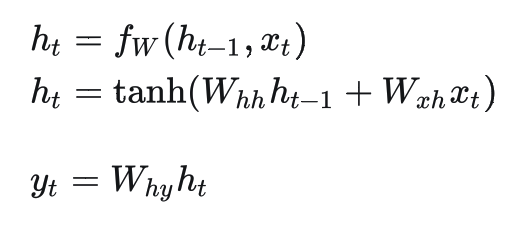
- 相比与典型的 RNN,Mamba 去掉了 tanh 非线性激活,促进并行运算;
- Mamba 的 Hidden state 维度比较大,对于每维都单独学习
- 在 Mamba 中,A 矩阵设计比较高级
- Mamba可以 Input-dependent(像 Transformer),灵活性(建模能力)高
以上就是 Mamba 整个系列知识。我感觉这个模型本身不难,重点是一系列的背景知识,包括状态空间模型 SSM 以及改进的 S4 模型 。了解完背景之后mamba 本身就会比较容易,改动实际上也并不大(不关注计算部分),就是 参数还未完全搞明白。
整个理解下来,感觉要用在姿态估计领域,还是有点点悬,就是这里一直声称是超长序列建模,我感觉精度会不如 Transformer,不过比较新,值得一试,我感觉可以试试 sequence-sequence 的姿态估计方法。要么就是说,把像素看成 token,就会有很长的序列,就可以说 transformer 会退化,而 Mamba 效果会比较好。下一步应用的话需要看相关的论文 + 代码。