DeepLearning中另外一个常见的问题就是分类问题,这里以二分类为例。
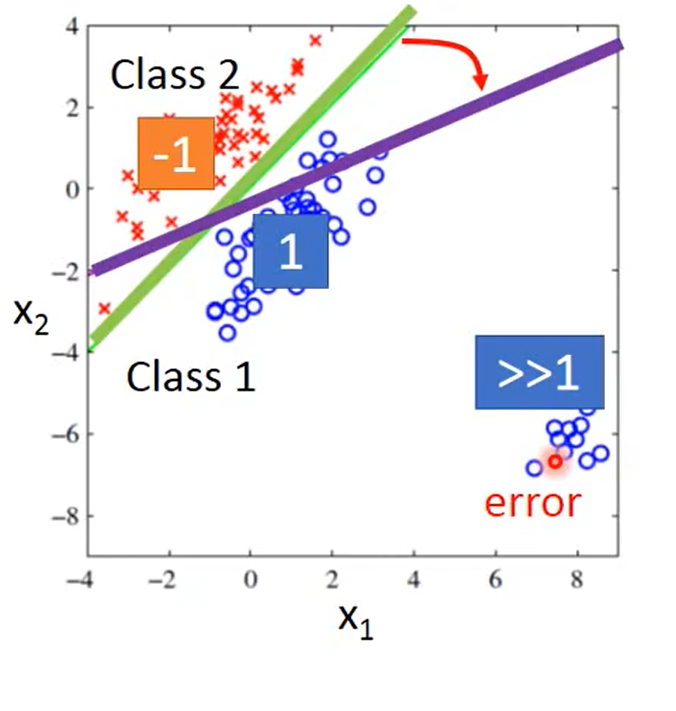
*做二分类可不可以直接当作回归问题来处理呢?例如人为规定 calss1 对应输出值为1, class2对应值为-1,然后以均方误差为loss,做损失函数,这样直接train是可以train出来的,但是这样有一个问题,回归损失函数会惩罚比较大的正确项,例如一个数得出来结果是10远大于1,但是它和1明显是一类,而用回归做的话就会尽量减小这一loss,导致出现错误的结果,如下图:本来绿色的线是正确的分类,但是因为回归的惩罚会导致偏向紫色。 这是因为回归和分类的判断标准不一样。
分类流程

- 这里的model直接用的贝叶斯求出概率
- 假设x服从高斯分布,此时要求出 μ,σ 用最大似然估计使得这个高斯分布所采样出来的这些点的概率最大
- 求解最优的μ,σ。μ 就是一组书的均值mean , μ,σ都有对应公式,也可以根据微分来求,如下图:
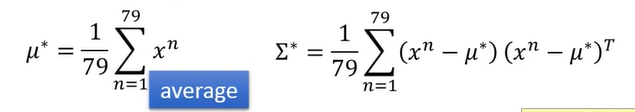
分类与回归的转化
这里用图片截图出所有的公式推导,可以从第一张图直接跳到最后一张图看结论
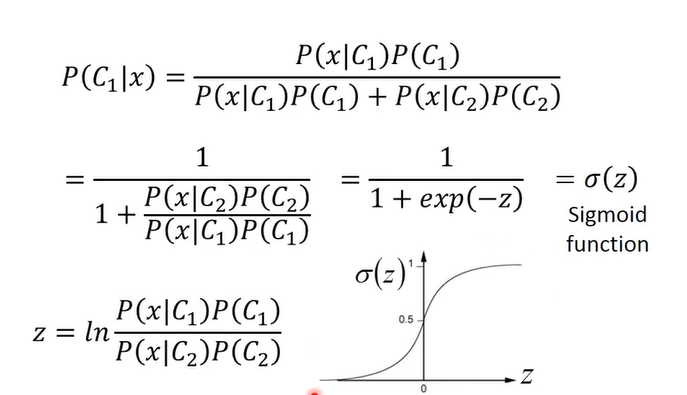
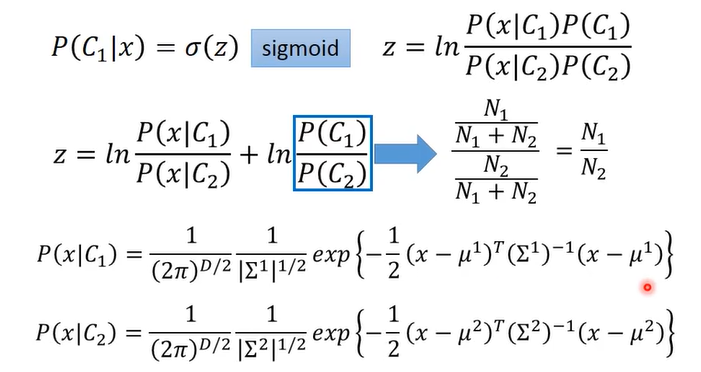



也就是说分类函数经过一系列的转换,最终变成了线性函数,即 P(C1|X) = σ(w * x + b),之前的方法我们要求五个参数才可以计算到最终结果,现在我们可以直接计算w,b就可以得到最终的概率!此时就变成了回归问题。然后就有了后面的逻辑回归,用交叉熵求出w,b
同时以上公式也说明了为什么 σ函数可以用来分类!