Problem
Batch Normalization 批标准化 ,在传统的深度学习没有批标准化时,存在以下一些问题:
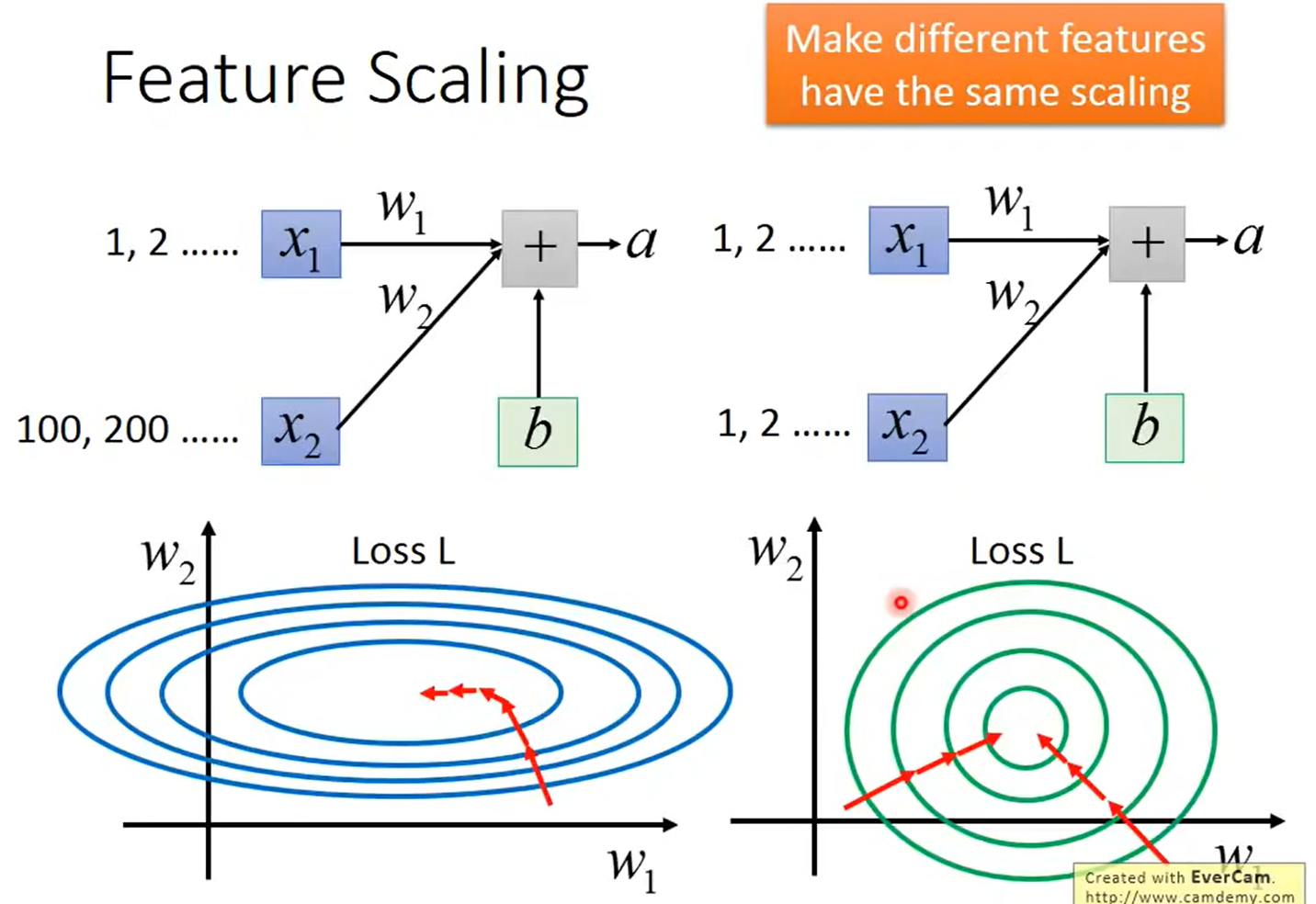
- 难以训练、拟合 例如下图,x1值为比较小,x2则很大, 整体公式是
a = w1*x1 + w2*x2 + b,此时就是图中左下角的图,w1影响就非常小了,相应的w1方向梯度就很小,w2方向梯度变化就非常大,这会使得模型难以训练、难以拟合。
-
Internal Covariate Shift 内部协变量偏移
神经网络有很多的隐藏层,每层都是以前一层的输出作为自己的输入,因此要对每一层做
Feature Scaling, 这样会比较有效的解决该问题。Internal Covariate Shift问题 大致意思是强一层便宜会对后续产生很大的影响,每层的输入如果不做特征缩放,很大很小模型就需要一直调整去适应,就需要把每层的输入都固定下来
Feature Scaling
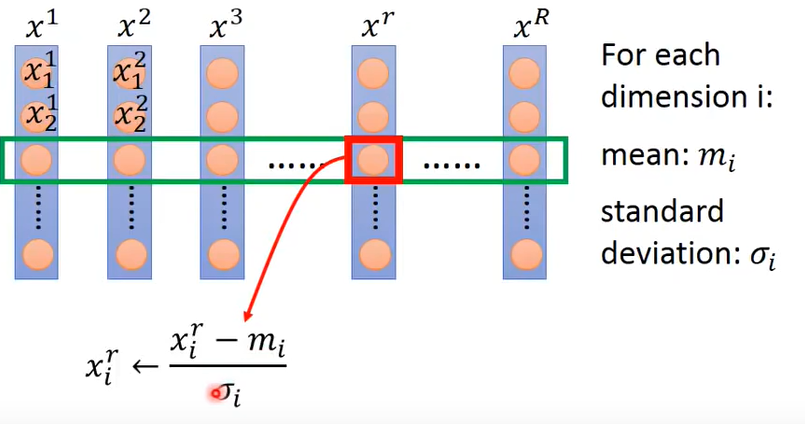
这种方法比较简单,对于每一维数据,计算平均数、标准差,然后每个数减去平均数除以标准差即可标准化。
Batch Normalization
Note :
- batch_size 要够大才有意义,估算batch的分布。如batch_size 为1,则没有意义做这件事。
- 一般先做标准化在进入激活函数
流程
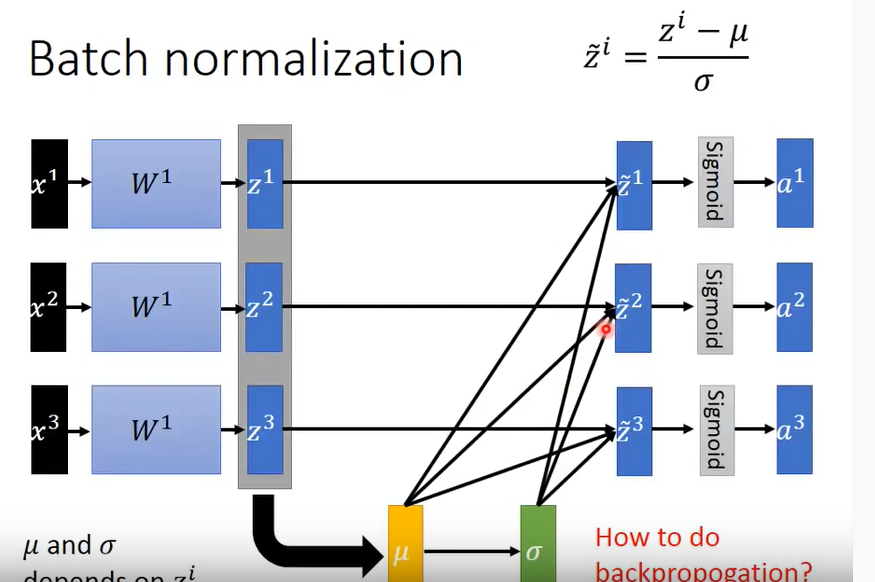
- 首先计算出 一个batch的平均值、标准差

- 具体的每个输出 - mean / 标准差
-
train:训练时反向传播需要考虑到 σ μ
-
test:测试
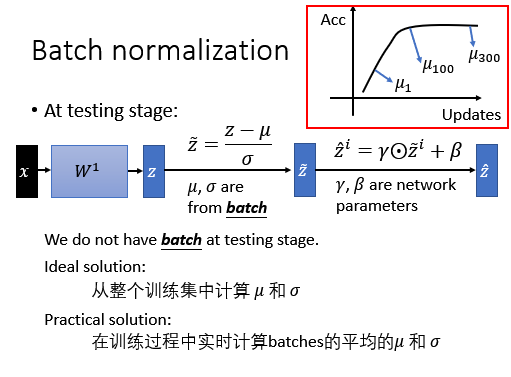
- 首先计算出训练过程中所有的 **σ μ **
- 如上图的右上角 取三个 μ,靠近后面的 μ 给一个比较大的权值,靠近初始化的给比较小的权值以此来估计整个网络的 μ
Batch Normalization好处
- 解决了 Internal Covariate Shift 问题,可以设置比较大的学习率,增加训练速度
- 可以有效防止梯度弥散 。之前讲sigmoid函数在比较深的网络是训练不起来的,因为梯度会消失,而每次采取了标准化,数据分布会比较靠近0附近,函数在此处斜率比较大,梯度会一直比较大
- 对参数初始化不是那么敏感。例如所有的w都变成 w*k,但是经过公式推导经过标准化最终并无任何影响
- 一定程度上解决过拟合 标准化从其实一定程度相当于正则化。
Batch Normalization 在训练效果不好时可以使用,而测试效果不好则不一定要采用该方法。