Attention背景
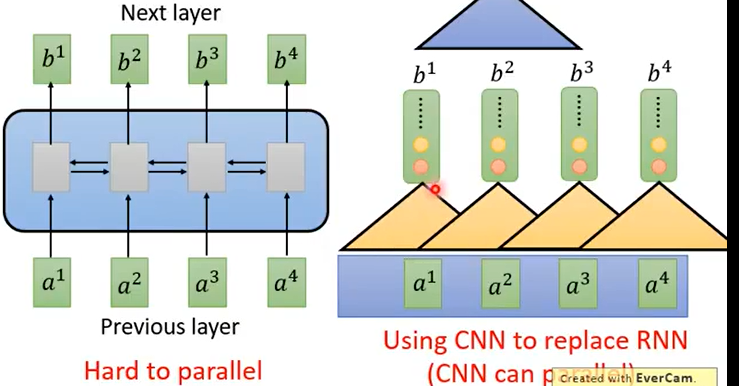
RNN循环神经网络,具有一定的记忆性,但是有一个固有的缺点就是不能并行运算,要算后一个必须就要先算出前一个。显示提出了CNN假设,用CNN替代RNN,此时已经可以并行计算,但是CNN必要有很多层才可以看更长时间的东西。
因此出现了Attention这种方法,成为RNN的代替方案。
计算流程
计算出 Q,K,V
首先输入x计算出a,a分别乘上三个矩阵得到q,k,v。
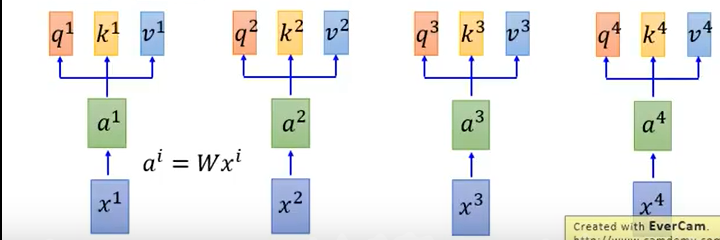
- 其中q表示query,查询,也就是用来做匹配;
- k表示key,是被匹配的对象;
- v表示value,是要被抽取出来的信息
用每个q对k做Attention
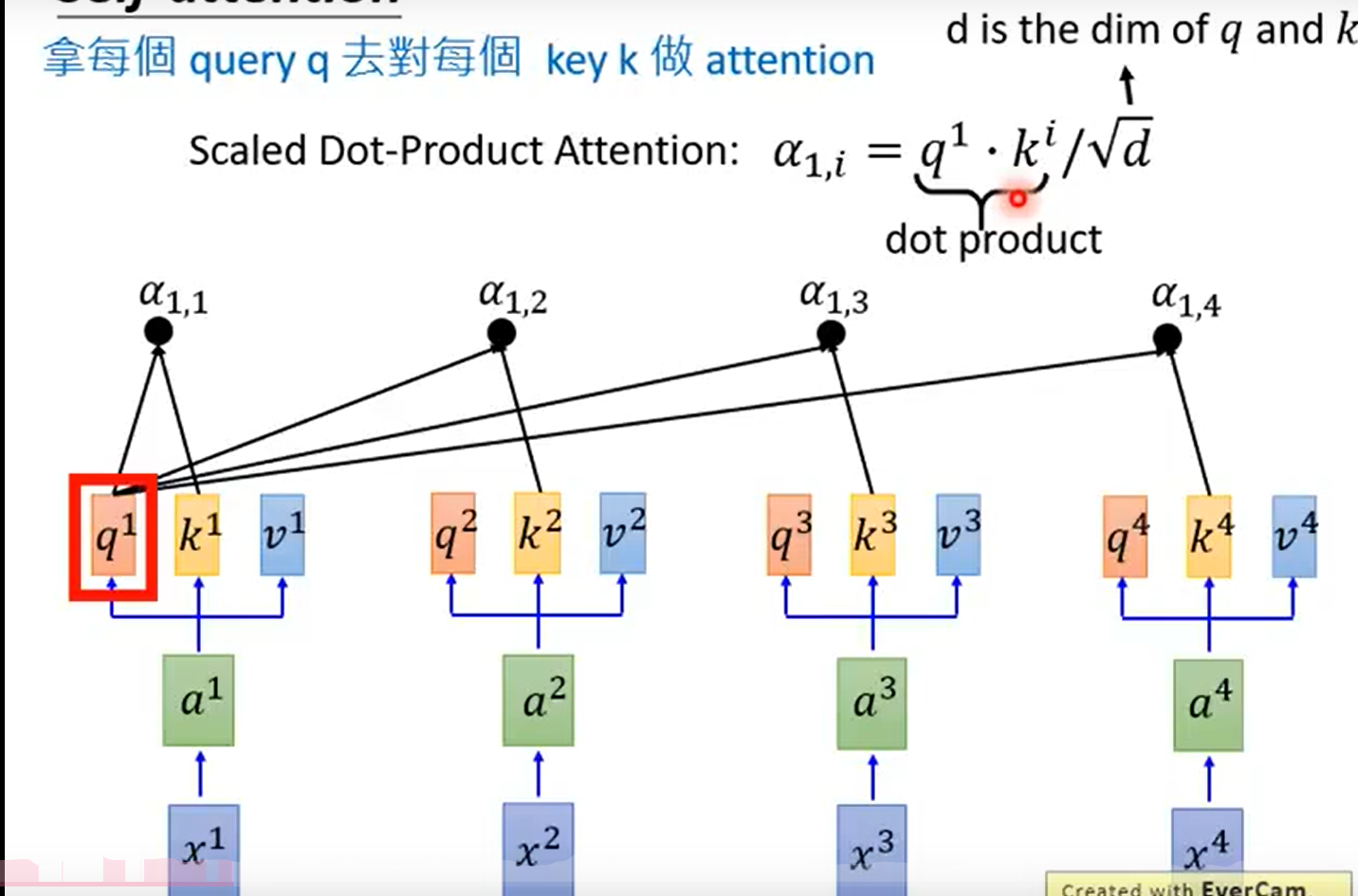 $$
\alpha_{1,i} = q_1 \cdot k_i / \sqrt d
$$
其中,q和k做内积除以它们的维度。d是q和k的维度。这个注意力计算公式也可以是其他的。
$$
\alpha_{1,i} = q_1 \cdot k_i / \sqrt d
$$
其中,q和k做内积除以它们的维度。d是q和k的维度。这个注意力计算公式也可以是其他的。
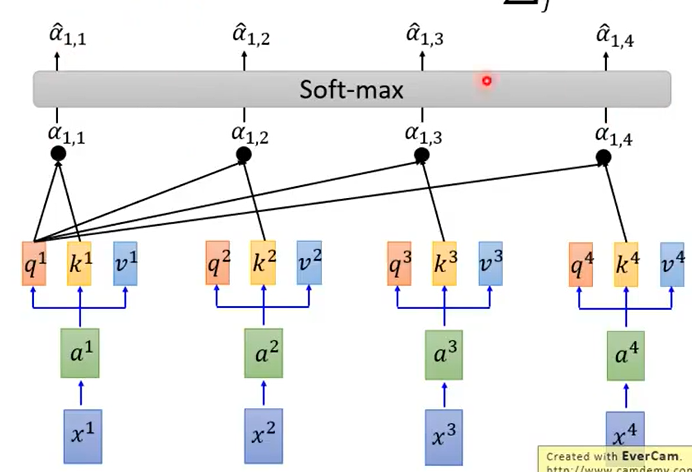
其中α经过softmax层得到α帽
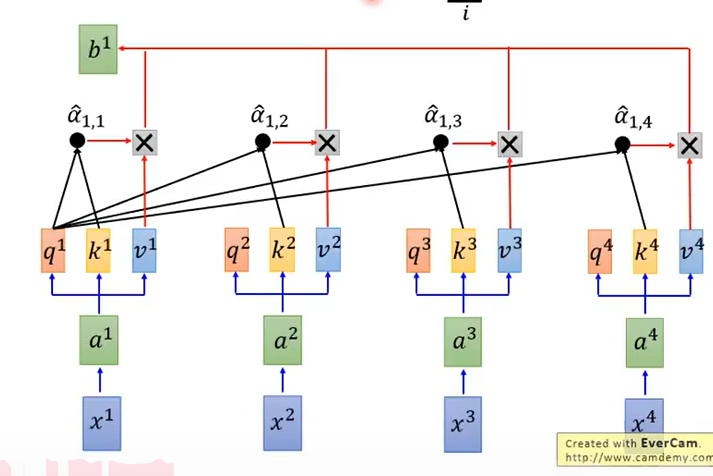
α帽和相应的v做一个加权和得到b,即:
此时,b1就已经考虑了整个的次序。
b2,b3,b4流程和b1一模一样,即:
并且是可以并行计算的。
并行运算细节
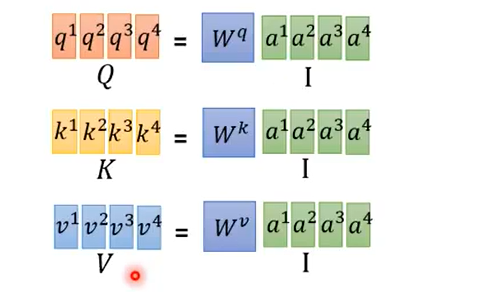
首先是Q,K,V三个矩阵,把a堆起来乘以w矩阵得到Q矩阵,K,V类似,这就可以同时计算。

把k堆起来乘以q可以得到α,经过softmax得到α帽。
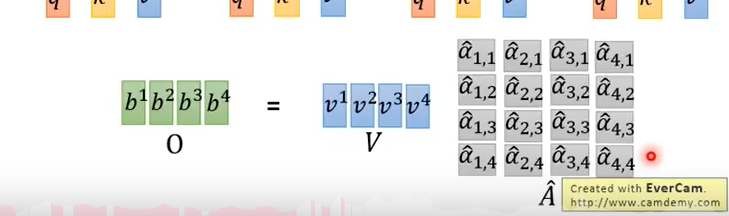
此时把v堆起来,就可以计算得出b1,b2,b3,b4.堆起来就是最后的输出。
位置信息
此时Attention其实是没有考虑时间次序的,因为q对每一个k都会做Attention,不管远近都会做,所以时序信息是没有考虑进去的。
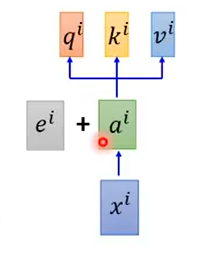
此时只要给ai加上一个ei矩阵即可。
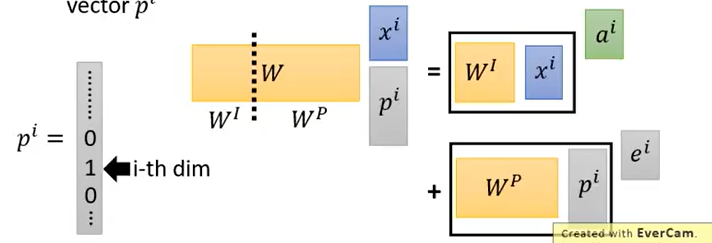
此时可以解释为给输入xi拼上了一个onehot向量,用来代表是哪个输入,然后得到上面的式子。
这只是大概讲了一下 Attention怎么计算,具体的NLP中怎么应用可以深究一下,但我不是做NLP的,所以大概了解就可以。
不求甚解如我。关于封面,Attention顾名思义,注意力,所以封面更能体现Attention。