Intra-frame Attention
Cross-frame Attention
-
(Personalized Feature Extraction module)个性化的图像特征抽取 (Insatnce-aware)
在 CNN Backbone抽取出特征之后,使用Deformable Conv进行个性化特征提取
5帧 cat-conv
basicblock 序列特征
-
self-feature refinement (VIT / VItPose)
- 输入是当前帧
- Multi-head self-attention
- 48 patch transformer
- 8 block
-
cross-frame interaction / temporal learning (MHFormer)
- q当前 hrent+可形变+vit
- k v序列 序列特征 basicblock
- 先算self-attention,再算有交互的
- Multi-Frame Cross-Attention
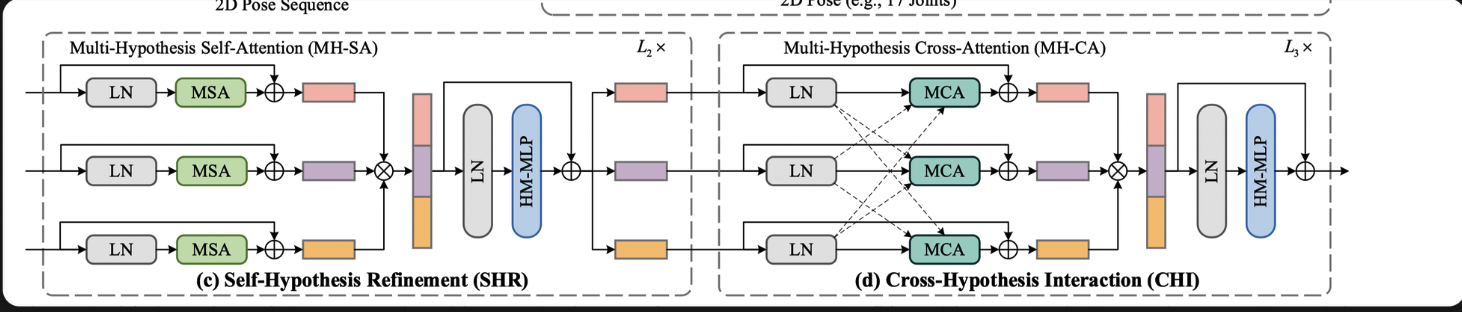
-
disentangled keypoint decoder (Bottom-up keypoint regression )
-
[batch,48,96,72] 3*3 [batch,1,96,72]
-
用17个CNN,每个输出1个通道
-
用17个head 分别去解码每个关节的heatmap
分关节考虑计算,17个head,关节解耦合
Novelty:
- 全局局部模型架构,整个流程说一下
- 以当前为查询 去序列特征搜索,建模更相关的特征
- 解耦合(decoupling/disentanglement)的关键点解码
- 效果好
Experiments:
PoseTrack17:
88.9037 | 89.6823 | 85.5904 | 79.5469 | 84.2159 | 83.1099 | 75.8414 | 84.179
PoseTrack18
84.3253 | 87.4536 | 83.463 | 78.5233 | 80.8873 | 80.2367 | 74.4472 | 81.5332
Sub-JHMDB
Split1: 0.994 | 0.9905 | 0.9609 | 0.9334 | 0.9913 | 0.9212 | 0.9369 | 0.963 Split2: 0.9929 | 0.9826 | 0.9217 | 0.8782 | 0.9915 | 0.9169 | 0.9576 | 0.9516 Split3: 0.9923 | 0.9846 | 0.9469 | 0.9311 | 0.994 | 0.9189 | 0.9651 | 0.9646
Mean:
-