看到一篇相关论文《LoftUp: Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models》,可实现更好的特征上采样质量,因此可应用于姿态估计网络生成质量更高的热图。
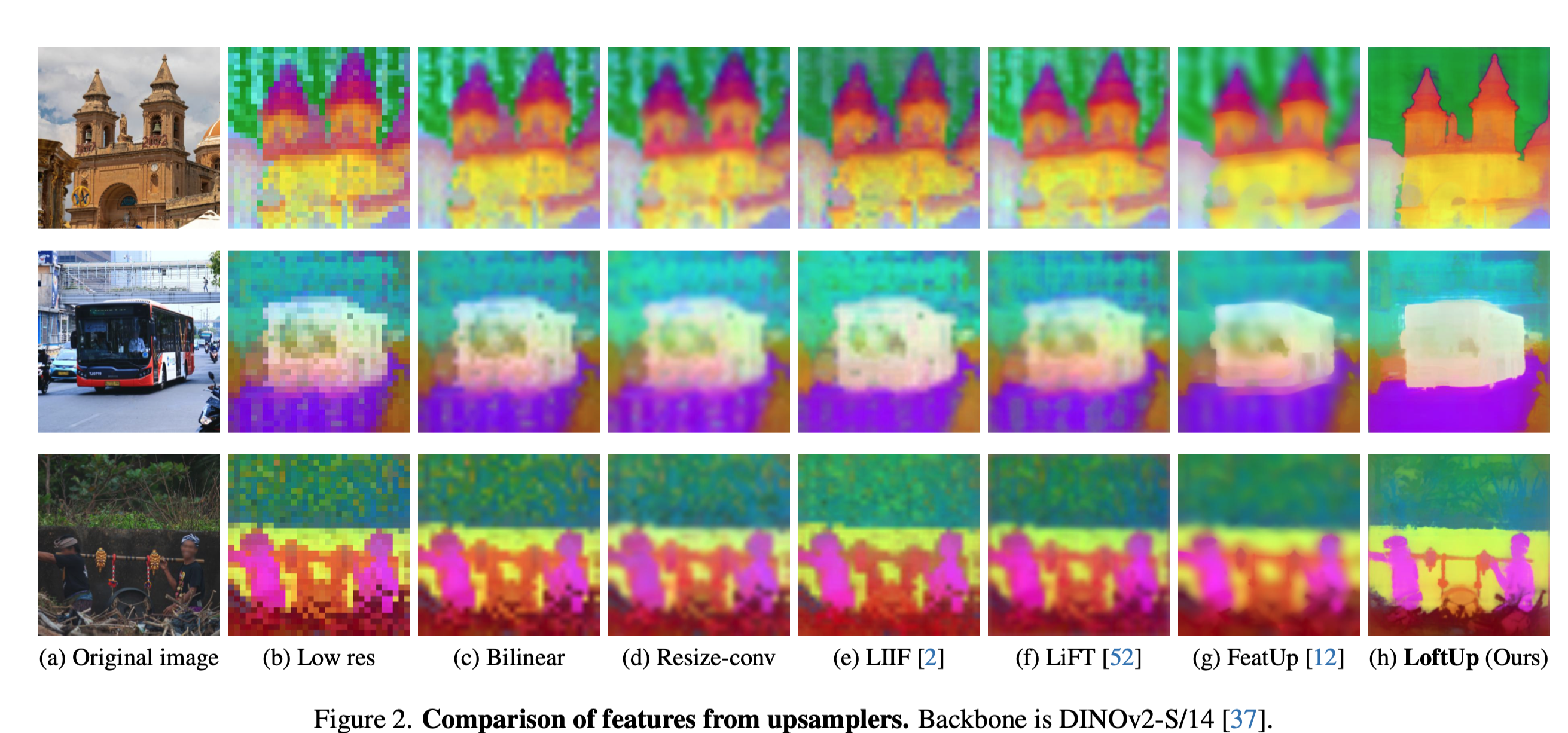
主要 idea 是用了坐标表示,即高分辨率下坐标和图像一起输入提取特征;然后作为 query,与低分辨率特征做 cross-attention。
如果把上采样作为一个创新点,那么就得想一下其他的创新点:
- 精心设的 heatmap 上采样,提高姿态估计精度 (比如 ViT 低分辨率,固定 ViT Backbone, 然后后面拼接上高级的上采样,看看效果)