基本概述
最近发现傅里叶变换经常会用于视觉领域,3D 姿态估计比较多。以下是相关论文的大致总结:
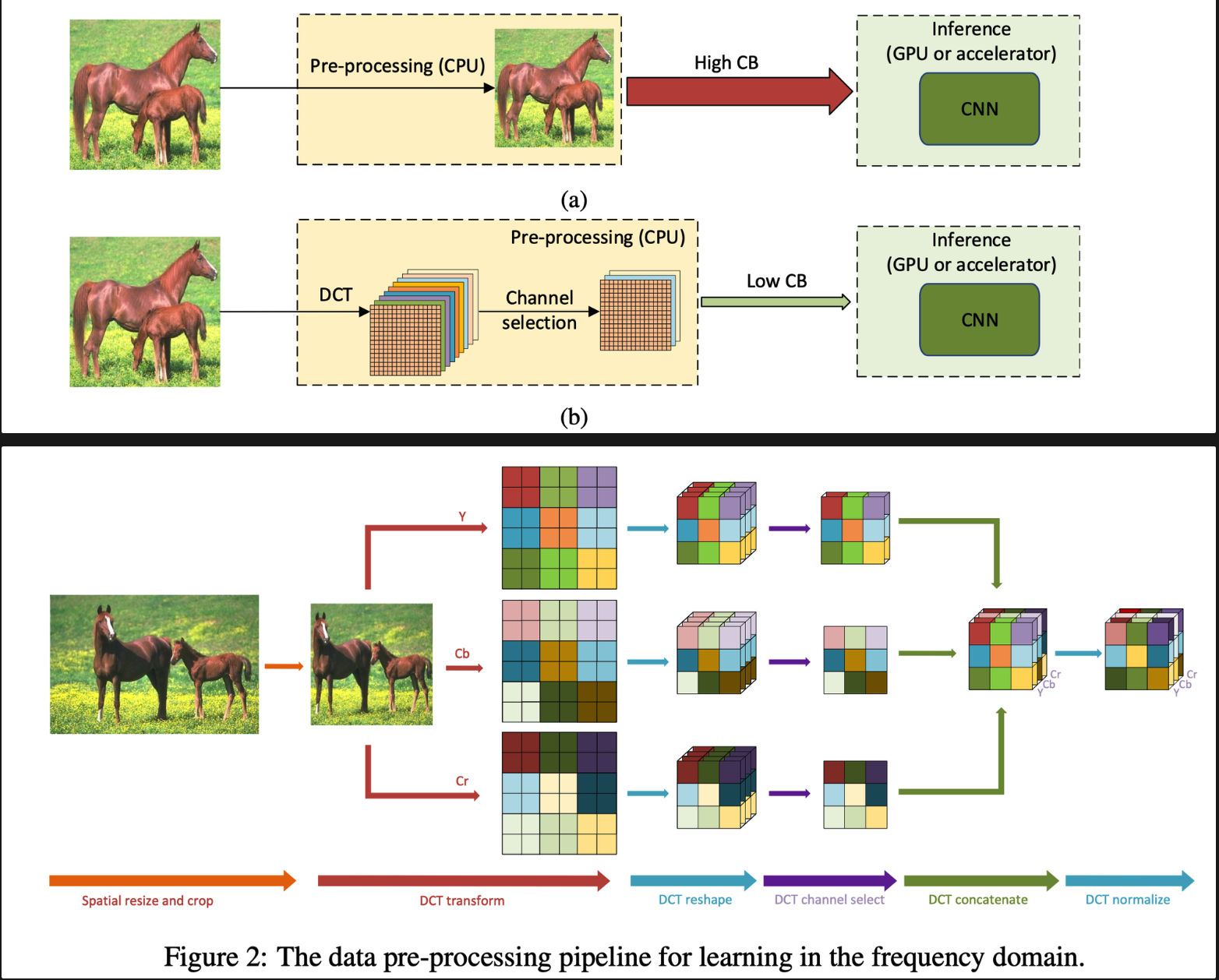
《Learning in the Frequency Domain》
!
-
做输入数据维度压缩。先有方法一般是先下采样图片,会导致信息丢失。所以 follow JPEG 编码格式,先把图转到频域,然后挑选重要的通道(类似 SENet)。
《Global Filter Networks for Image Classification》

-
现有的 Transformer/MLP 风格的模型都是依靠计算图像 token 之间的交互。本文将 token 转到频域,然后用一个可学习的滤波器调整频域特征,然后转回空域。
-
更加计算高效
-
这篇论文很多的理论信息可以学习一下
《Exploring Temporal Frequency Spectrum in Deep Video Deblurring》
一般来说 video 需要时-空建模,这篇论文引入时-频建模。
3个基本论点:
- The blurred degradation can be better modeled in the frequency domain. 频域可以更好的建模运动模糊
- The frequency spectrum can enlarge the unpredictable change of temporal motion blur. 空间域模糊的图形变化不大,但是他们的频域时间变化是更大的
- The blur degradation may decay the energy spectrum of the sharp videos. 更清晰的视频/frame 包含的能量更大
整体框架:
把频域建模整合到 特征提取-对齐-聚合-优化(loss)Pipeline 中
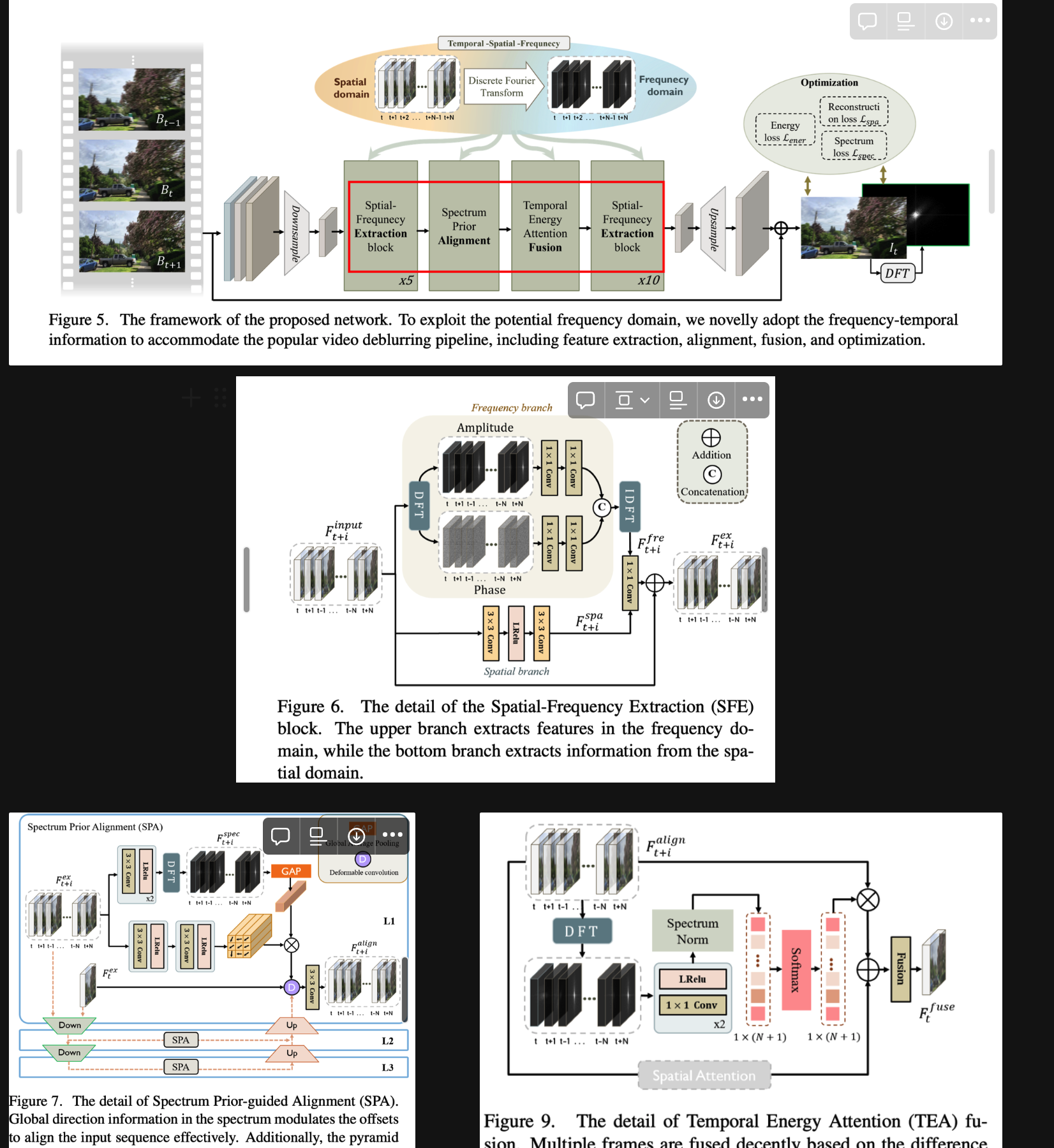
- 融合频域和空间信息提取,频域来建模模糊;
- 用频域全局运动信息引导特征对齐 <这里我感觉可以把输入序列换成差分,就可以是显式的全局运动信息了> (输入序列学习到的 offset 用频率信息重新赋权重,改进的话可以用学到的进一步调整 modulated scalar)
- (现有方法特征融合时是直接加法,遮挡/模糊/清晰的特征系数都一样的)本文用频域引导特征融合,直接用 softmax 把多帧频域特征变成权重,清晰的频域特征能量更大,自然而然的就会给更清晰的图像帧特征分配更多的权重 || 这个我觉得很重要,相当于是一种新的特征聚合方法。
IDEA:*********************************
感觉基于这篇论文,可以做一篇期刊:
从频域中学习增强的时序对齐和聚合
- 对齐方面,先有方法由于有限的卷积核难以把握全局运动信息,且在图像模糊下会难以察觉到运动变化;我们用傅里叶变换,首先在频域建模能够提取全局的运动信息;其次傅里叶本身能量信号是可以提高对模糊、(遮挡等,这种情况需要验证)运动信息的建模能力的,因此可以提高 offset 以及 mask 的学习;这里可以直接用 HRNet 第四个阶段特征,做multi-scale对齐。在这里用傅里叶的时候可以加一个可学习的 filter 来提高适应性建模
- 聚合方面,直接聚合多帧信息不可避免会用到模糊等信息,傅里叶则可以自适应的配分更多权重给清晰的(有用的、准确的)特征。 | 由粗到精的聚合,先用傅里叶做 framelevel 的reweight,然后用 channel attention 做每个帧内部的调整,然后再聚合
- 监督方面,可以考虑 heatmap 的傅里叶优化,直接 l2 在遮挡等情况会不规则导致量化误差,傅里叶强迫学习更多的细节 heatmap
《Multi-Frequency Representation Enhancement with Privilege Information for Video Super-Resolution》
提出使用频域的一个好的理由:CNN 感受也小;VIT 计算量太大;频域则可以填补这个 gap;传统的频域方法用固定的系数直接转换;我们用一个课学习的提高适应性
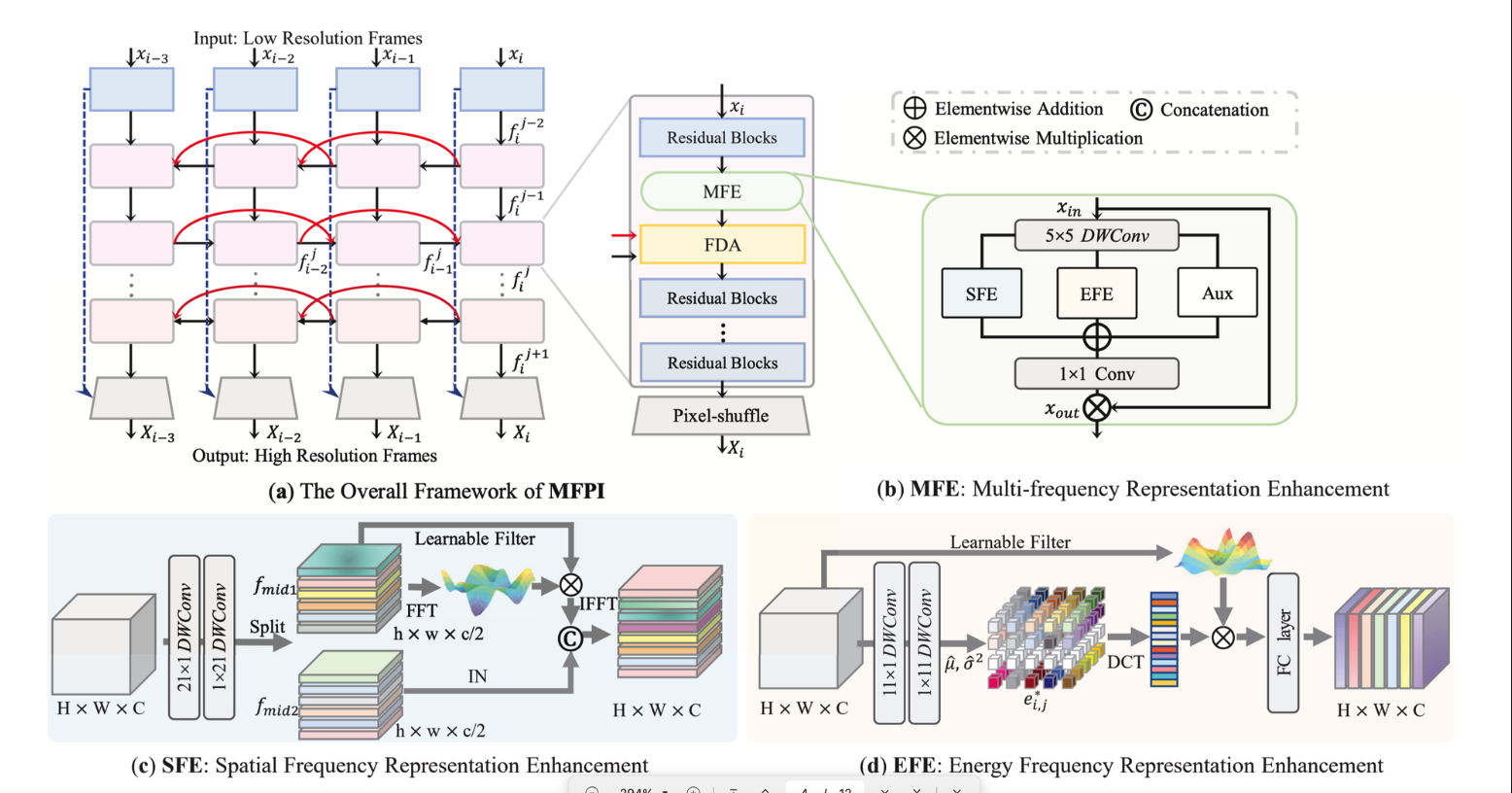
(c)空间频域表示增强 — — — 傅里叶变换具有全局性;大核卷积也具有全局性;两者共同保证全局依赖;可学习的 filter+IN 保证泛化性
(d) 能量频域表示增强 — — — — 增强通道间的交互
感觉可以学之前论文,做一篇傅里叶的全流程探索论文
有几个重点:
- 傅里叶怎么更好地在时序中应用,不能有轻模块嫌疑,也就是说得找一种好的时序建模方法
- 解决了第一点就简单了
把频域信息整合到空间特征提取-时序交互-优化流程中。
探索时空建模在频域中
探索时空频谱
Idea-1
Motivation:
现有方法采用双流网络,一个分支使用 CNN融合多帧信息来建模时空特征,另一个分支用光流/时间梯度来建模运动。这样的流程有两个缺点:
- 时空和运动建模均在像素空间,受CNN 很有限的感受野的限制。本文提了一个频域增强的时空模块,从频域角度探索增强的时空表征;以及一个频域运动模块,计算频域的时间梯度来提取全局运动信息。
- 双分支网络在推理期间比较 cost,例如光流很慢。为了解决这个问题,本文提出一个新的基于胡信息的蒸馏策略,显式蒸馏细粒度的运动知识并且施加不同模态的一致性,从而在推理期间无需运动建模分支。
相比 SOTA,本文获取了多少 mAP vs 多少性能。
感觉可以学习一下特征蒸馏的思想
Idea-2
傅里叶+四维运动矩阵 做姿态估计